The Post-Platform Engineering Era: A Practitioner's Reality Check on Autonomous DevOps
Over the past decade, Platform Engineering has matured into a stable practice: paved roads, curated toolchains, Kubernetes clusters, GitOps workflows, observability platforms, and automated build pipelines. Even most observability platforms can now accept code as configuration, rather than point-and-click dashboards. Yet the operational surface area of modern systems keeps expanding. Docker containers are convenient, but each one introduces a new OS to patch, secure, monitor, and audit. Even well-designed platforms still depend on humans to interpret signals, investigate anomalies, and turn raw data into meaningful action. And the workload itself is exploding—more dependencies, more configurations, more data to process, more alerts to triage, more vulnerabilities to fix, more compliance checks to satisfy. In short: the complexity is accelerating faster than our ability to manage it.
I do believe however we are now entering a new phase—one where AI agents, connected across the DevOps feedback loop, begin shifting systems from merely automated to truly autonomous. Instead of teams manually triaging security findings, updating Dockerfiles, or validating patches, we're approaching an era where infrastructure can interpret, reason, and act on its own. Almost. And the key point is: we can already build early versions of this today with the tools we already use.
And frankly, at the rate the space is evolving, by 2027, companies without autonomous DevOps will face 2-3x higher operational costs compared to those leveraging it!
Most Companies Won't Reach Autonomous DevOps Because Their Foundations Are Broken
Here's the uncomfortable truth: although autonomous DevOps is possible, most companies won't get there anytime soon. After 25 years in this industry—and more recently navigating the realities of a large-scale SaaS transformation—it's painfully obvious that the barrier is not AI sophistication but organizational and technical foundations. The proverbial "technical debt", so to speak!
Most companies still operate with:
- fragmented architectures
- tribal knowledge
- inconsistent environments
- snowflake pipelines
- half-adopted declarative practices
- missing ownership boundaries
- monitoring without observability
- “platforms” that were never treated as products
AI can't coordinate what the organization itself hasn't aligned. If the platform is inconsistent, the codebase fragmented, and the tooling scattered, autonomous DevOps doesn't eliminate the chaos—it amplifies it.
Autonomy is not a tool you bolt on top; it's an outcome you earn by having clean foundations.
The Shift Toward Autonomous Infrastructure
The idea is straightforward: when every stage of the DevOps cycle is observable, structured, and reachable by an AI model, the entire loop becomes connectable. Observability systems produce signals. CI/CD pipelines emit metadata. GitOps controllers enforce declarative state. In such an environment, AI agents become the coordination layer—interpreting events, generating work items, proposing fixes, and even preparing merge requests.
DevOps evolves from human-driven automation into a semi-autonomous ecosystem where agents retrieve signals, propose investigations, and initiate remediations, while humans supervise, approve, and set the guardrails.
In order to achieve this level however, many transformations will be required, including reconfiguring the organization around AI agents (i.e. a new org chart).
In Order to Achieve This Transformation, a New Org Chart Will Be Required
And here's the next hard truth: this shift requires new roles, and some existing roles will disappear. Just as cloud-native practices reshaped the responsibilities of sysadmins, autonomous DevOps will reshape Platform Engineering, SRE, DevOps, and Security teams.
In the emerging model, we will need:
- Autonomy Engineers — designing the feedback loops and guardrails
- AI-Augmented SREs — supervising agent behavior rather than reacting to alerts
- Platform Product Managers — treating the platform as a living product, within the Ops organization
- Governance Engineers — defining policies and ensuring safe automation
- Cross-Functional “Loop Stewards” — responsible for supervising AI-driven decision flows
And as autonomy increases, manual roles like release coordinators, operational triage teams, and pipeline babysitters naturally diminish.
This isn't about replacing people; it's about transforming the nature of the work, figuring out accountability, skill gaps and security concerns of an semi-autonomous DevOps loop.
From Signal to Action: The Autonomous DevOps Loop
Modern AI coding tools don't just automate existing steps—they fundamentally change how the loop behaves. As well as waiting for signals, AI can actively explore codebases, dependency graphs, changelogs, configuration files, and operational history to identify risks before they become incidents.
A quick reference for the DevOps loop from ByteByteGo (I highly recommend that blog and YouTube channel!)
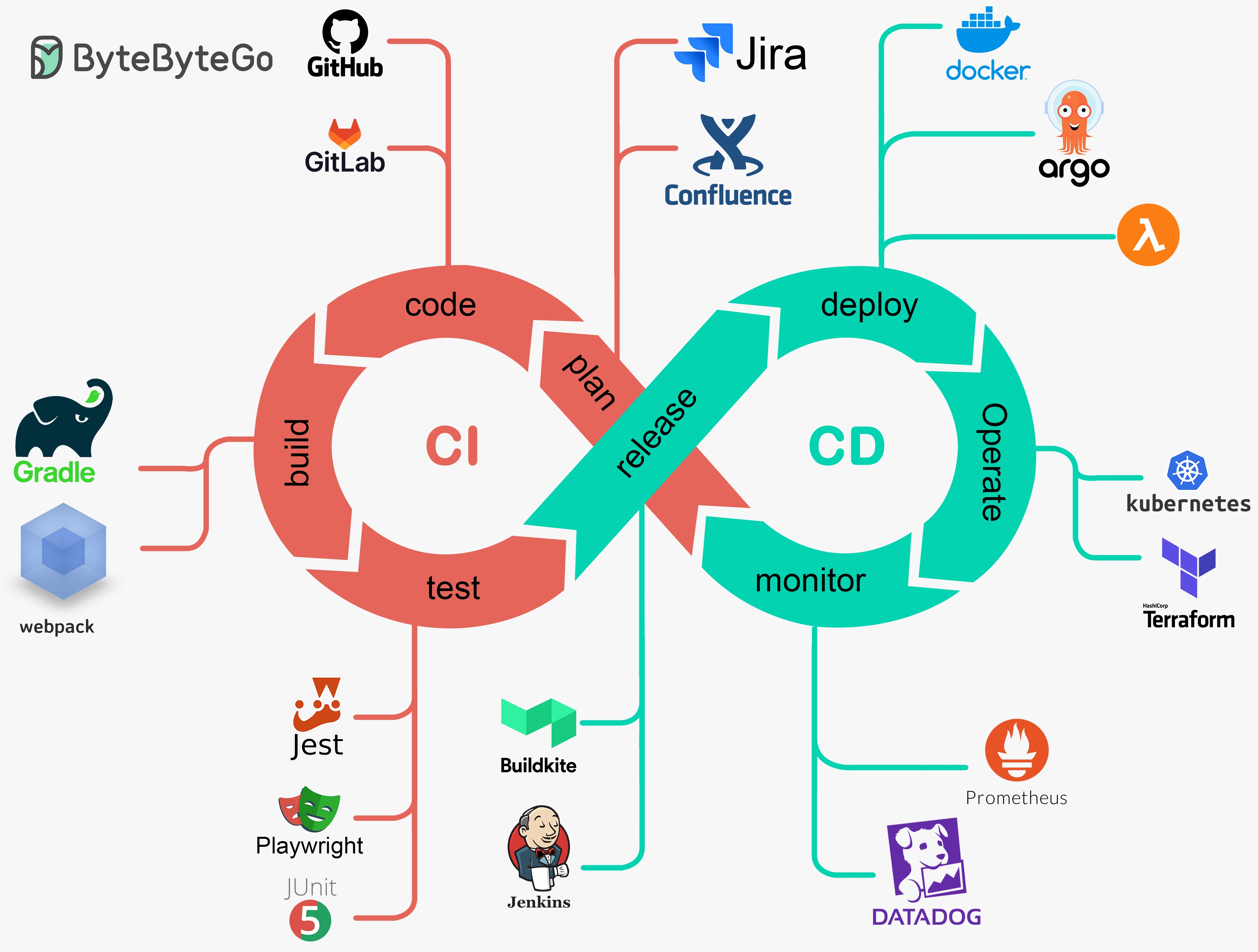
1. Plan - Signal
Traditional signals still matter—DAST scans, runtime anomalies, dependency vulnerabilities. But proactive signals emerge as well: outdated base images, deprecated APIs, libraries nearing end of support, or patterns in recent merges that correlate with instability. AI tools can surface these early by continuously reviewing the repository rather than waiting for scanners. AI can continuously review changelogs, dependency evolution, and operational data to propose roadmap items or preventive improvements.
2. Plan - Interpretation
Once those inputs have been identified and items are created within our overall backlog, the interpretation shifts from observing a single alert to understanding the broader development context: recent refactors, version drift, dependency clusters, or modules that frequently introduce issues. Instead of reacting to one CVE, the system can map out the entire impact surface across services and forecast related risks.
3. Plan - Decomposition
Instead of generating a task per signal, whatever the signal is, the AI agent can review the entire context of the application and codebase and group related items into cohesive tasks or workstreams: a set of outdated libraries, an entire chain of Docker images that require upgrades, or multiple services dependent on the same vulnerable module. This creates fewer, clearer work items with better context and broader corrective impact.
4. Code - Autonomous Investigation
Investigation becomes more holistic. Rather than only patching the discovered issue or completing the item identified as improvement, the AI agent can:
- review the full dependency tree to identify upstream or downstream risks,
- suggest consolidating versions across services to reduce divergence,
- examine the changelog of libraries to detect breaking changes before upgrading,
- propose structural improvements such as replacing deprecated APIs or cleaning unused modules.
The value here is not the patch — it is the opportunity to eliminate entire classes of future alerts.
5. Build, Test, Release & Deploy - Execution Through GitOps
During the Build phase, agents introduce proactive checks that catch structural issues before compilation. They analyze dependency graphs, detect incompatible versions, and recommend consolidations that reduce drift across services.
In the Test phase, they generate or modify tests automatically — expanding coverage where risk is predicted, adapting cases when libraries evolve, and surfacing the scenarios most likely to fail.
This flows naturally into Release, where AI identifies opportunities to align versions, remove deprecated components, and coordinate updates across the ecosystem. Instead of reactive hotfixes triggered by a single alert, releases become structured improvements that reduce future noise.
Finally, during Deploy, GitOps controllers apply a unified set of changes proposed by the agents. Instead of one-off patches, the system delivers coordinated merge requests: dependency upgrades, image improvements, configuration cleanups, and version realignments. Deployment remains declarative and auditable, but the changes being deployed are now systemic rather than tactical.
This cohesive workflow ensures that fixes address root causes, not just symptoms — strengthening the entire platform as changes propagate through the GitOps pipeline.
6. Operate & Monitor - Verification
In the autonomous model, Operate and Monitor merge into a unified verification phase where the system evaluates not just whether things are functioning now, but how they are likely to behave in the near future. Instead of focusing on isolated alerts, AI agents analyze runtime behavior holistically—looking for systemic patterns, drifts, and correlations across services. This allows them to detect early signs of instability long before they would trigger traditional monitoring thresholds.
Verification expands from a narrow question—“Did the alert disappear?”—into a broad, forward-looking assessment. Agents test new versions against known regression signatures, validate compatibility with dependent services, and simulate workloads to uncover subtle breakpoints. They correlate logs, traces, and performance metrics across environments to understand how changes propagate through the platform. When discrepancies appear, the system can propose corrective actions or additional patches before issues mature into user-visible incidents.
In this model, Operate and Monitor become continuous, anticipatory disciplines. The platform verifies not only that the current state is healthy but that future states will remain stable, reducing surprises and reinforcing reliability across the entire ecosystem.
How to Build a Basic Version Today
A first-generation autonomous DevOps loop can be assembled today using existing AI features embedded in monitoring, planning, and CI/CD platforms, as well as properly managing for the context of the AI agents (see references below). You don't need custom agents—just the right connections between tools already in the ecosystem.
Modern monitoring platforms like Datadog can automatically open Jira issues from alerts or anomalies, while GitLab Secure, Snyk, or Trivy provide structured findings for vulnerabilities and misconfigurations. From there, AI-powered interpretation layers such as Jira Rovo AI, GitLab Duo, and repo-aware command-line tools like Claude Code, OpenAI Codex, or the Gemini CLI can read the code, explore dependencies, and attach meaningful summaries or suggested actions.
Once an issue is created, the decomposition and investigation steps can be handled by these same tools. They can analyze dependency graphs, identify version drift, spot breaking changes, and even generate patch diffs. This turns raw signals into clear work items or ready-to-review merge requests. Execution remains governed by GitOps. GitLab CI runs the usual pipelines while FluxCD applies the changes automatically once approved. Verification is supported by AI-driven analysis tools like Datadog Bits AI, which review logs and metrics after deployment to confirm the fix or highlight follow-up actions.
In practice, this creates an early autonomous loop using only off-the-shelf integrations:
- Signal & Issue Creation: Datadog → Jira
- Interpretation & Context: Jira Rovo, GitLab Duo
- Investigation & Patches: GitLab Duo, Claude Code, Codex, Gemini CLI
- Execution: GitLab CI + FluxCD
- Verification: Datadog Bits AI
A lightweight but functional autonomous workflow—built entirely from widely available tools.
The ROI isn't necessarily reducing straight up FTEs, but reducing the time spent on repetitive, low-value tasks or increasing our bandwidth to do those repetitive, low-value tasks necessary for a solid platform.
Conclusion
The move toward autonomous infrastructure is not a hype cycle—it's already materializing inside the platforms we use every day. Monitoring tools now raise issues on their own, AI systems interpret code and dependencies with precision, security scanners generate structured insights, and GitOps engines apply changes safely across environments. Together, they form the early scaffolding of systems that understand their own health, anticipate risks, and act before problems emerge.
But autonomy won't simply “arrive”. It requires strong foundations, disciplined engineering cultures, and organizations willing to rethink their structures (human and technical). The companies that succeed will be the ones that treat their platforms as ecosystems, not just pipelines; and their engineers as designers of systems, not executors of tickets.
What emerges is not full autonomy—but a far more practical evolution: platforms that reduce noise, avoid repeated failures, and continuously harden themselves with minimal human intervention. This is the post-platform engineering era—an era already underway for the prepared few, teams prepared to pay down their technical debt, connect the tools sitting right in front of them, and evolve the roles around them. And it will only succeed in organizations willing to challenge every long-standing assumption, especially in the security industry, where paperwork is still mistaken for protection and unnecessary complexity is too often equated with safety. Autonomous systems will force all of us to prioritize engineering rigor over ritual, and measurable outcomes over checkbox exercises.
References
- The Rise of the AI Engineer
- The Rise of the Cognitive Architect
- YouTube Video: No Vibes Allowed: Solving Hard Problems in Complex Codebases - Dex Horthy, HumanLayer
- ByteByteGo
AI Usage Disclosure
This document was created with assistance from AI tools. The content has been reviewed and edited by a human. For more information on the extent and nature of AI usage, please contact the author.