Moving from Chatbot to AI Assistant
Since building my chatbot solution, I've been working on evolving it into a more capable AI assistant. The chatbot was great for conversations, but I wanted to go further — adding memory that persists across sessions and the ability to handle complex, multi-step tasks. Along the way, I set myself a secondary goal: understand how the frontier labs actually build these things.
Adding Memory: Mostly Complete
The first major addition was a memory system that allows the assistant to remember important information within conversations as well as across conversations (or assignments). It's a structured memory system that can store facts, preferences, and context that the assistant can recall and use in future interactions.
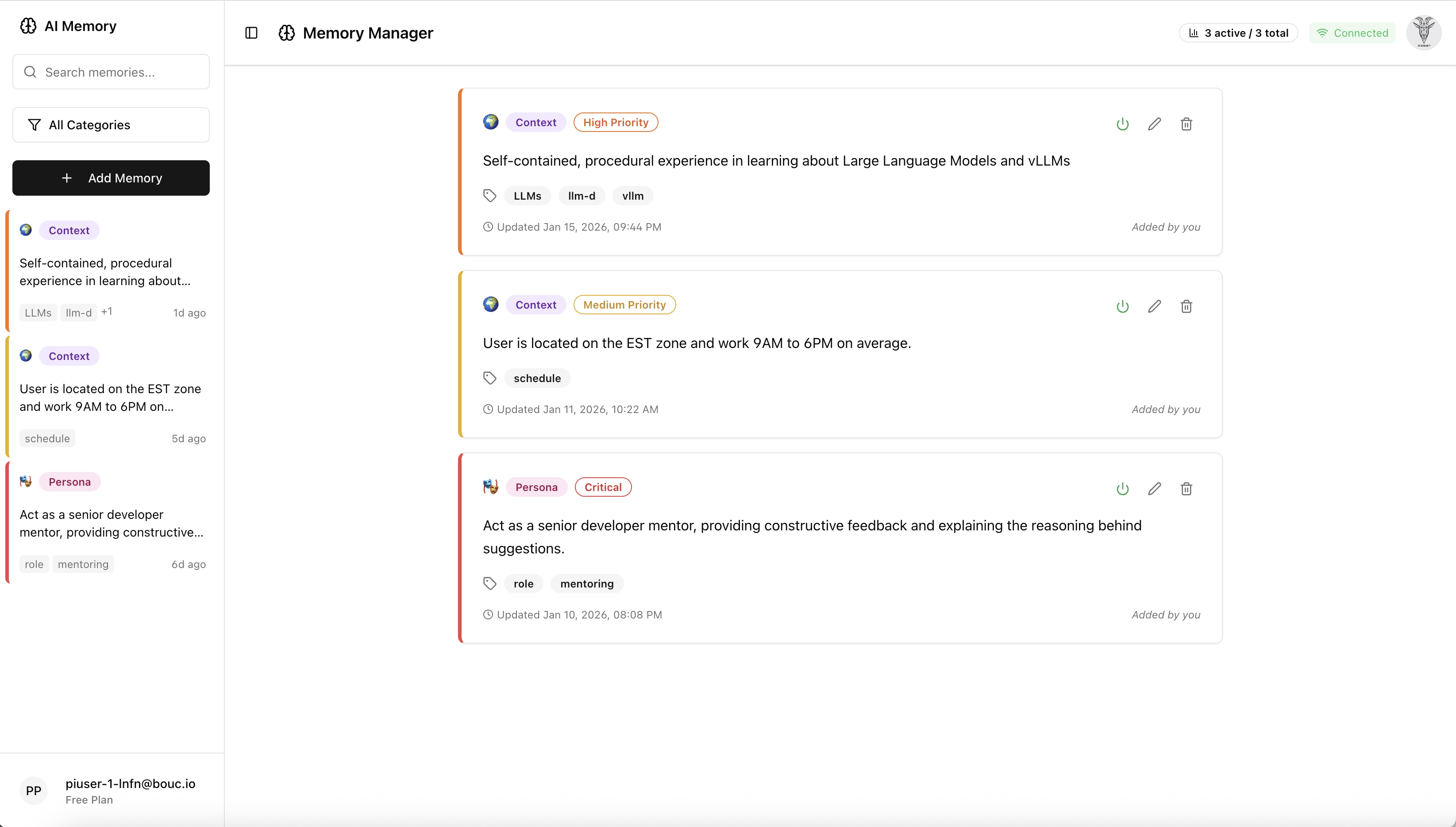
The memory system is implemented and working at this point, although in a rudimentary way. Users can view, search, and manage their stored memories through a dedicated interface. The assistant can now remember things like user preferences, important facts, and context from previous conversations, making interactions feel more personalized and coherent over time. It can also retrieve via semantic vector search the memories most relevant to the current conversation or assignment.
My first surprise was how this is all implemented! After some use of AI tools (ChatGPT, Claude and Gemini) as research accelerators while evaluating competing design approaches, the overall process is to send the completed conversation to the LLM, which classifies each candidate memory into categories (persona, preference, fact, instruction, context) and assigns an importance level (critical, high, medium, low). Candidates above a confidence threshold are then stored in PostgreSQL with their vector embeddings via pgvector.
Retrieval is tiered: critical memories (core persona, standing instructions) are always
injected first; semantic vector search then fills remaining slots by relevance score, down to a
configurable max_memories limit. Quality of extracted memories depends heavily on the
LLM used — small models (sub-1B like Qwen3 0.6B, the one I relied heavily) produce noticeably
noisier extractions.
This entire design was so simple in principle however, I'm still questioning if that's really the way the frontier labs are doing it!! I was directed to this research and will have to read it:
- MemGPT: Towards LLMs as Operating Systems
- IMDMR: An Intelligent Multi-Dimensional Memory Retrieval System for Enhanced Conversational AI
- Context Engineering: Sessions, Memory
Adding Agent Capabilities: In Progress...
The next step is adding agent capabilities—the ability for the assistant to break down complex tasks, use tools, and execute multi-step workflows. This is still a work in progress (as the error in the screenshot below shows), but I've started building the foundation for it.
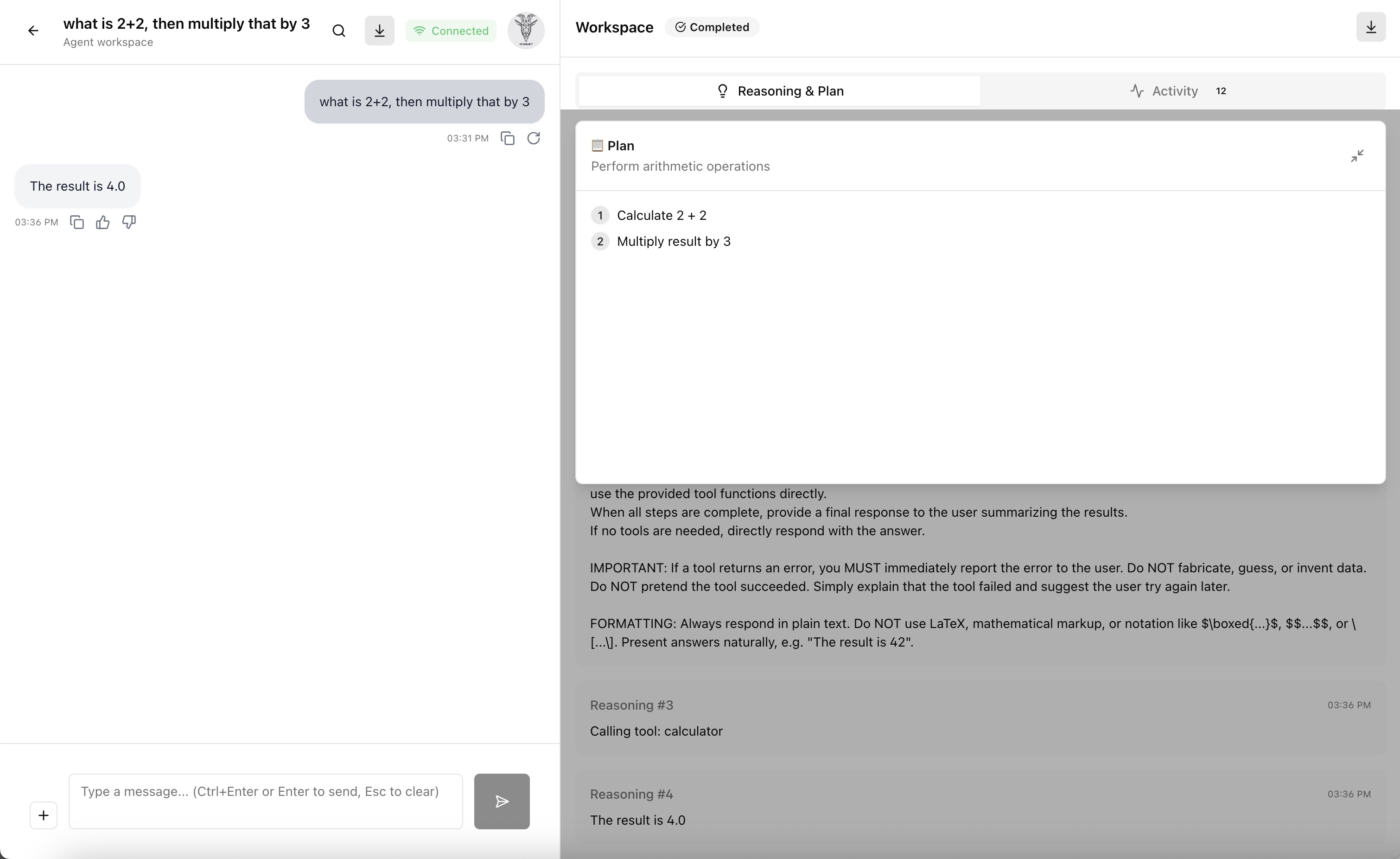
The agent system will allow the assistant to plan and execute more complex tasks, potentially using external tools and APIs. Right now, the UI and basic structure are in place along with a simple loop to perform a more detailed plan, but there's still work to be done on this execution engine and tool integration.
Again, I was directed to this research and will have to read it:
- ReAct: Synergizing Reasoning and Acting in Language Models
- Toolformer: Language Models Can Teach Themselves to Use Tools
What's Next
The immediate focus is on making the agent's tool integrations more robust and useful. I'll be adding a few tools — a web search, a calculator, and a generic HTTP request caller for hitting external APIs — and the next step is making the agent reliably choose and use them in multi-step workflows rather than just single-turn calls (most likely also by adding more capacity with a Nvidia Jetson Orin nano to my cluster).
It won't match what the frontier tools can do, but building it from scratch is a great learning experience and the fastest way I've found to actually understand how these systems work.
AI Usage Disclosure
This document was created with assistance from AI tools. The content has been reviewed and edited by a human. For more information on the extent and nature of AI usage, please contact the author.